เป็น programming language สำหรับการคำนวณทางสถิติและแสดงกราฟฟิกโดยเฉพาะ ได้รับการพัฒนามาเพื่อทดแทน S language ที่พัฒนามาเป็นซอฟท์แวร์ทางการค้า S-PLUS (บริษัท Insightful) S-Plus เป็นโปรแกรมคำนวณทางสถิติที่ได้รับความนิยมเป็นอย่างมากอันหนึ่ง โดยภาษา S ได้รับการพัฒนาในช่วงปลายทศวรรษที่ 80 โดย AT&T lab ส่วนภาษา R นั้นเริ่มได้รับการพัฒนาโดย Robert Gentleman และ Ross Ihaka จากภาควิชาสถิติ มหาวิทยาลัยโอคแลนด์ ประเทศนิวซีแลนด์ในปี 1995 ในปัจจุบันอยู่ภายใต้การดูแลของทีมพัฒนาซึ่งเป็นอาสาสมัครจากทั่วโลก R พัฒนาขึ้นมาแบบ open-source ทำให้สามารถดาวโหลดโปรแกรมมาใช้ได้"ฟรี"ซึ่งมีอยู่บนหลายแพล็ตฟอร์มเช่น Unix, Linux, MS Window ซึ่งล่าสุดได้รับการพัฒนาถึงเวอร์ชั่น 2.0.1 แล้ว (stable version)โดย R language มาพร้อมกับเอกสารแนะนำเบื้องต้น และเอกสาร Help นอกจากนี้ยังสามารถอ่านเอกสารเฉพาะทางซึ่งเขียนโดยผู้เชี่ยวชาญในด้านนั้นๆได้จากเว็บไซต์ด้านบนเช่นกัน นอกจากนี้แล้วแหล่งข้อมูลที่สำคัญอีกที่คือ R-help mailing list ซึ่งสามารถค้นหาคำถามและคำตอบหรือจะสมัครเพื่อรับและส่งอีเมล์กับกลุ่มดังกล่าวก็ได้เช่นกัน และโดยทั่วไป R ถูกพัฒนาขึ้นมาทดแทน S ดังนั้นเอกสารของ S-PLUS จึงสามารถใช้ได้กับ R ได้เช่นกัน
ในปัจจุบันมีหนังสือที่เขียนแนะนำการใช้ R ในการคำนวณสถิติมากขึ้นเรื่อยๆ ดังเช่น
Peter Dalgaard. 2002. Introductory Statistics with R (Statistics & Computing). Springer-Verlag New York Inc.
William N. Venables, David M. Smith. 2002. An Introduction to R . Network Theory Ltd
John Fox. 2002. An R and S-PLUS Companion to Applied Regression. Sage Publications Ltd
John Maindonald and John Braun. 2003. Data Analysis and Graphics Using R: An Example-based Approach. Cambridge University Press
Kimberley Seefeld, Michael Reich, Ernst Linder. 2004. R for Bioinformatics. O'Reilly UK
ในเอกสารนี้จะใช้ R เวอร์ชั่นบนแพล็ตฟอร์ม Microsoft Windows โดย R จะมาพร้อมกับ RGui ซึ่งเมื่อคลิ้กที่โปรแกรมก็จะปรากฏหน้าต่าง R console ขึ้นมาอย่างในภาพด้านล่าง และต่อไปในส่วนที่เป็นโค้ดหรือผลที่ได้จากการรันใน R จะแสดงอยู่บนพื้นหลังสีดำเพื่อให้ต่างกับเนื้อหาอื่น
จากเมนู Help > Html help จะทำการเปิดเอกสารที่มากับโปรแกรมด้วยเว็บบราวเซอร์ เช่นเอกสารแนะนำการใช้เบื้องต้น หรือค้นหาคำสั่งและรูปแบบการใช้งานและคำอธิบายพร้อมตัวอย่าง
จุดที่เห็นเครื่องหมาย > นั้นคือหมายถึงว่าเป็นจุดสำหรับการป้อนคำสั่งต่างๆ เริ่มต้นเราจะดูการใช้ built-in function สำหรับแสดงวิธีการเขียนอ้างอิงหากนำ R มาใช้ในการคำนวณ โดยใช้คำสั่ง citation()
> citation()
To cite R in publications, use
R Development Core Team (2003). R: A language and environment for
statistical computing. R Foundation for Statistical Computing,
Vienna, Austria. ISBN 3-900051-00-3, URL http://www.R-project.org.
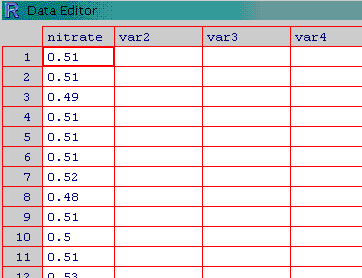
เมื่อกรอกครบแล้วให้คลิกขวา เลือก close เพื่อปิด spreadsheet และ R จะทำการเก็บข้อมูลให้โดยอัตโนมัติ เมื่อกลับมาสู่หน้าต่างหลักแล้วให้ลองเรียกดูข้อมูล ก็จะได้ดังนี้
คำนวณช่วงความเชื่อมั่นของค่าเฉลี่ยของความเข้มข้นไนเตรตจากตัวอย่างข้างบน (ขนาดตัวอย่างคือ 50) จากสูตร ช่วงความเชื่อมั่นคือ mean ± z*sigma/sqrt(n) โดยค่า z คำนวณได้สำหรับที่ความเชื่อมั่นต่างๆ ด้วย qnorm() นั่นคือค่า inverse ของ cumulative distribution function
> Na=c(102,97,99,98,101,106)
> t.test(Na)
One Sample t-test
data: Na
t = 75.2575, df = 5, p-value = 7.848e-09
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
97.0672 103.9328
sample estimates:
mean of x
100.5
นั่นคือช่วงความเชื่อมั่นที่ 95% คือ 100.5±3.4
> t.test(Na,conf.level=.99)
One Sample t-test
data: Na
t = 75.2575, df = 5, p-value = 7.848e-09
alternative hypothesis: true mean is not equal to 0
99 percent confidence interval:
95.11542 105.88458
sample estimates:
mean of x
100.5
> x<-c(50.4,50.7,49.1,49.0,51.1)
> t.test(x,mu=50.0,conf.level=0.95)
One Sample t-test
data: x
t = 0.1404, df = 4, p-value = 0.8951
alternative hypothesis: true mean is not equal to 50
95 percent confidence interval:
48.87358 51.24642
sample estimates:
mean of x
50.06
> t.test(x,y,var.equal=TRUE)
Two Sample t-test
data: x and y
t = -0.8811, df = 10, p-value = 0.3989
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.940597 1.273931
sample estimates:
mean of x mean of y
57.00000 57.83333
เมื่อเราคำนวณค่า statistic t แล้วเราก็จะทำการเปรียบเทียบค่านี้กับค่า critical value t (df=8) ซึ่งปรกติสามารถเปิดดูตาราง t-distribution ได้หรือสามารถคำนวณด้วย R ได้เช่นกัน เช่นที่ (P=0.05) ใน R ด้วยคำสั่ง qt() จะให้ค่า t สำหรับ one-tailed test ดังนั้นในกรณีนี้เราต้องการสำหรับ two-taied test นั่นคือที่ P=0.05 เราต้องคำนวณโดยการใช้ค่า P=0.025 แทน
ดังนั้นค่า t จากการคำนวณ (4.56) มีค่ามากกว่า critical value (2.31) ดังนั้นค่าเฉลี่ยจากสองวิธีมีความแตกต่างกันอย่างมีนัยสำคัญ ที่ 5% level และจริงแล้วค่า critical value สำหรับ t ที่ 1% จะมีค่าประมาณ 3.36 นั่นคือความแตกต่างมีนัยสำคัญที่ 1% level
หรือเราสามารถใช้ t.test() โดยตรงได้โดยการสร้างข้อมูลดิบหลอกขึ้นมาโดยใช้คำสั่ง rnorm() ซึ่งเป็นการสร้างตัวเลขสุ่มสำหรับการกระจายแบบ Normal โดยหากต้องการสร้างตัวอย่างแบบเทียม (psudo random sample) จำนวน n ค่าที่มี่ค่าเฉลี่ย mu และ ค่าเบี่ยงเบนมาตรฐานเป็น sigma เราสามารถสั่งใน R ได้ดังนี้ x<-mu+sigma*scale(rnorm(n))(คำแนะนำจาก R-help mailing list)
> a<-1.48+0.28*scale(rnorm(5))
> b<-2.33+0.31*scale(rnorm(5))
> t.test(a,b,var.equal=T)
Two Sample t-test
data: a and b
t = -4.5499, df = 8, p-value = 0.001875
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.2807971 -0.4192029
sample estimates:
mean of x mean of y
1.48 2.33
> normal<-c(1.84,1.92,1.94,1.92,1.85,1.91,2.07)
> rheumatoid<-c(2.81,4.06,3.62,3.27,3.27,3.76)
> sd(normal);sd(rheumatoid)
[1] 0.0755929
[1] 0.4404884
> t.test(normal,rheumatoid)
Welch Two Sample t-test
data: normal and rheumatoid
t = -8.4772, df = 5.253, p-value = 0.0002937
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.004938 -1.082205
sample estimates:
mean of x mean of y
1.921429 3.465000
> a<-c(84.63,84.38,84.08,84.41,83.82,83.55,83.92,83.69,84.06,84.03)
> b<-c(83.15,83.72,83.84,84.20,83.92,84.16,84.02,83.60,84.13,84.24)
> t.test(a,b,paired=T)
Paired t-test
data: a and b
t = 0.8821, df = 9, p-value = 0.4007
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.2487527 0.5667527
sample estimates:
mean of the differences
0.159
มีความสงสัยว่าในการไตเตรตมีความผิดพลาดของตัวอินดิเคเตอร์และทำให้ได้ผลมากกว่าเป็นจริง นั่นคือมี positive bias จึงทำการตรวจสอบด้วยการใช้สารละลานกรดเข้มข้น 0.1 M พอดีไตเตรตสารละลายด่างเข้มข้น 0.1 M พอดีปริมาตร 25 mL ได้ผลดังนี้ (mL): 25.06, 25.18, 24.87, 25.51, 25.34, 25.41 เราสามารถตรวจสอบ positive bias ของผลนี้ได้ดังนี้
> titrant<-c(25.06,25.18,24.87,25.51,25.34,25.41)
> t.test(titrant,mu=25.00,var.equal=T,alternative=c("greater"))
One Sample t-test
data: titrant
t = 2.3473, df = 5, p-value = 0.03289
alternative hypothesis: true mean is greater than 25
95 percent confidence interval:
25.03232 Inf
sample estimates:
mean of x
25.22833
> signal=data.frame(a,b,c,d)
> signal
a b c d
1 102 101 97 90
2 100 101 95 92
3 101 104 99 94
> boxplot(signal, xlab="condition",ylab="Signal")
data.frame() เป็นคำสั่งในการสร้าง data frame ซึ่งเป็นรูปแบบการเก็บข้อมูลในรูปแถวและคอลัมน์อย่างที่แสดงในตัวอย่างด้านบน แต่ละคอลัมน์คือข้อมูลของสภาวะที่ต่างกัน และแต่ละแถวเป็นข้อมูลแต่ละซ้ำของการวัด หลังจากนั้นเราใช้ boxplot() พร้อมกับอ็อปชั่นในการกำหนด label แกน x และ y ตามลำดับเพื่อสร้างกราฟ
ในการทำการวิเคราะห์ ANOVA จะใช้ฟังก์ชั่น oneway.test() ซึ่งรับข้อมูลที่อยู่ในลักษณะที่มีหนึ่งตัวแปรเก็บค่า signal และอีกหนึ่งตัวแปรที่จะระบุกลุ่ม เราสามารถสร้างข้อมูลแบบนี้ได้ด้วยคำสั่ง stack()
> signal.stack=stack(signal)
> signal.stack
values ind
1 102 a
2 100 a
3 101 a
4 101 b
5 101 b
6 104 b
7 97 c
8 95 c
9 99 c
10 90 d
11 92 d
12 94 d
นั่นคือเราได้ข้อมูลที่ตัวแปรชื่อ values เก็บค่า และ ind บอกหมู่ของค่า
> oneway.test(values ~ ind, data=signal.stack,var.equal=T)
One-way analysis of means
data: values and ind
F = 20.6667, num df = 3, denom df = 8, p-value = 0.0004002